Alt-F4 #15 - Investigando la 1.1 27-11-2020
traducido por G00S3MEISTER

Tabla de contenidos
Esta semana, con la versión 1.1 experimental recién lanzada, echamos un vistazo a dos de las cosas que trae consigo. Primero, Conor_ investiga qué le permite hacer el nuevo límite de paradas de tren en su fábrica basada en trenes. Luego, Therenas explora lo que significa la actualización de múltiples subprocesos para las cintas transportadoras, tanto en la teoría como en la práctica. ¡Cuidado, puede que aprendas algo!
Limites en las paradas de tren Conor_
Cuando surgió el tema de hablar sobre los cambios que trae la versión 1.1, lo obvio que debo discutir es, por supuesto, la nueva función de límite de paradas de tren porque ¡me gustan los trenes! A continuación, analizaré qué problema resuelve esta función y cómo lo manejaba antes.
Un simple error de un jovén ingenuo, Conor_
Hace un tiempo, estaba construyendo una de mis primeras grandes bases para intentar vencer a SpaceX en coste de investigación 5x (porque ¿Por qué no?) Cuando me di cuenta de los problemas que surgen en mi red de trenes Spaghetti™. En mi ignorancia juvenil, había decidido que las paradas de un material dado debían compartir un nombre, desplegar una gran cantidad de trenes para que circulen entre estas paradas para garantizar que todos se utilicen. Esta no fue una buena idea. El sistema fácil de implementar me provocó un gran dolor y sufrimiento, algo que no había experimentado desde que traté de averiguar el procesamiento del petróleo. Me había funcionado bien en bases pequeñas con solo un par de paradas repartidas en una distancia corta, pero a gran escala los trenes simplemente no iban a los puestos exteriores que estaban más lejos. Algunas paradas estaban llenando y provocando atascos, mientras que otras estaban desiertas. Decidí que tenía que haber una solución mejor y, como buen ingeniero que soy, trabajé duro para investigar y desarrollar una mejor solución al problema pregunté en Reddit.
¿Alguien sabe de un mod que distribuirá por igual los trenes entre las paradas del mismo nombre, sin importar la diferencia de distancia? P.ej. Todas las paradas de descarga de hierro se llaman una cosa, pero un número igual de trenes van a cada una de las diferentes paradas.
Does anyone knows of a mod that will equally distribute trains between stops of the same name, irrelevant of the distance difference. E.g. All iron unload stops called one thing but an equal number of trains go to each of the different stops.
— Conor_ (Agosto, 2019)
Qué sueño tan encantador tuve allí. En lugar de lo que pedí, me señalaron con bastante razón TSM y LTN, luego me dijerón que continuara. Pero con 1.1, los desarrolladores gritaron desde lo alto: “¡Tenemos una nueva función para los trenes!” De acuerdo desarrolladores, teneís mi atención…
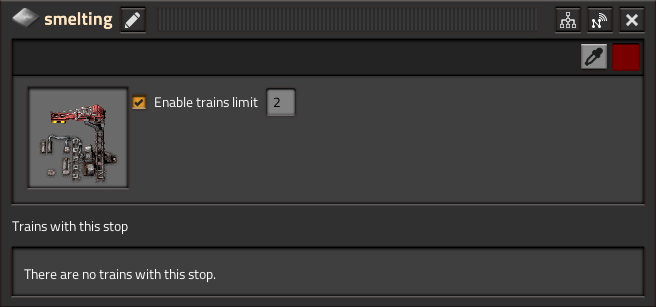
¿Qué son los límites de trenes en la parada?
El límite de trenes en la parada, como se explica en FFF-361, te permite establecer un límite en la cantidad de trenes en cualquier parada. Los detalles técnicos de este sistema se hablan mucho más en el FFF (que definitivamente vale la pena leerlo), pero, en esencia, un tren sólo debería ir a una estación si hay espacio para recibirlo, que es exactamente lo que quería el joven Conor. ¿Pero se sostiene en comparándolo con mi recién descubierto amor, TSM?
¿Qué es TSM y por qué debería importarme?
Train Supply Manager (TSM) es un mod que permite a las paradas de trenes solicitar un tren cuando se cumplen ciertas condiciones del circuito. Un ejemplo pertinente de tal condición sería solicitar un tren cuando menos de un cierto número de trenes están en camino a la parada. También te permite hacer mágia en circuitos más complejas, como solicitar un tren solo cuando hay suficiente material para llenarlo, aunque nunca he usado esta funcionalidad.
El sueño de TSM es implementar completamente un sistema de logística basado en pedidos en lugar del basado envios que se ve en configuraciones más básicas. Empujar es la estrategia habitual que puede encontrar en muchas fábricas más pequeñas donde los trenes se llenan en el puesto exterior y luego se envían para hacer cola en el destino. Con un sistema de tracción, los trenes siempre están listos para entregar o listos para ser cargados, y solo se solicitan (es decir, se retiran) cuando se necesitan recursos.
La diferencia aquí es donde se decide el horario de los trenes; para un sistema basado en envios, el tiempo lo dicta la rapidez con la que las paradas pueden llenar los trenes y enviarlos en su camino, independientemente de la cantidad de recursos que necesite la fábrica. Al cambiar a un sistema de pedidos, el tiempo lo deciden las paradas de destino, permitiéndoles solicitar trenes solo cuando realmente los necesitan. Esto le permite reducir enormemente la cantidad de trenes en movimiento en una red determinada y controlar dónde hacen cola los trenes para asegurarse de que no causen atascos. Aunque esto también es posible en vainilla usando grandes apiladores de trenes, planificar cuidadosamente dónde deben detenerse los trenes para esperar, no es muy ideal ni conveniente. En este sistema, los trenes se solicitan tanto en las paradas de recogida como en las de entrega, lo que es especialmente importante para bases más grandes y es la razón por la que amo tanto a TSM.
¿Pueden los límites de parada de tren reemplazar a TSM?
Para comprender si era necesario TSM en lugar de simplemente usar la nueva función de límite de paradas de tren, recreé la configuración de TSM en vanilla 1.1, sin TSM, con ¡gran éxito!
La razón por la que esto funciona tan bien y es un buen reemplazo directo para TSM es que los trenes esperan en la parada del depósito hasta que haya espacio en la estación de carga o descarga. Si los trenes esperaran en el lugar de carga, esto causaría congestión y limitaría la capacidad de producción del productor. El uso de paradas de depósito permite que los trenes tengan una especie de “área de parada”, para esperar hasta que se necesiten, fuera del camino del resto de la red de trenes.
Como podemos ver, la totalidad del sistema se puede recrear con la nueva función básica, probablemente con un mejor rendimiento debido a la propia naturaleza de la función. Esto ni siquiera explica la mayor simplicidad del límite de paradas del tren en comparación con la comprensión de TSM, que tiene una curva de aprendizaje bastante empinada y una documentación menos que perfecta. TSM aún puede ser útil en ciertos escenarios, como cuando el jugador quiere información sobre qué solicitudes no se han cumplido actualmente y que TSM proporciona a través de su interfaz, aunque yo personalmente rara vez uso estas funciones.
Conclusión
Una ocurrencia común para los juegos con soporte de mods es que los desarrolladores del juego vean una funcionalidad interesante de un mod y la implementen en el juego base. Esto puede ser un poco doloroso para los creadores de mods, ya que hace que su mod sea prácticamente obsoleto, pero al final, han logrado mejorar el juego. Su mod ahora está integrado indirectamente en el juego que aman, lo que significa que más personas pueden usarlo, lo cual es genial.
Un agradecimiento especial a sorahn en el servidor de Discord de Factorio por ver mis preguntas y hacer todo lo posible para ayudarme, haciendo el mapa que modifiqué anteriormente para ayudar a ilustrar como TSM puede trabajar en la configuración de “solicitud doble”, así como para verificar la cordura de mis ideas antes de construirlas.
Esta característica será asombrosa para los jugadores más nuevos (como el joven e ingenuo Conor_) para poder construir redes de trenes más grandes y más elaboradas, más fácilmente. Proporciona otra característica fácil de aprender y difícil de dominar para que los jugadores dedicados la usen y exploren, mientras ayuda a los novatos a divertirse.
1.1 Mejoras en el rendimiento Therenas
La versión experimental más reciente de Factorio trajo consigo muchos cambios, uno de los cuales quiero analizar más de cerca hoy. Se esconde dócilmente en el registro de cambios 1.1.0 y no se ha mencionado en ninguna edición de FFF antes del lanzamiento. Son solo seis palabras: Lógica multiproceso de las cintas actualizada. Estoy aquí para averiguar qué significa eso y qué impacto tiene realmente.
¿Cómo funciona esta optimización a nivel técnico?
Ahora, es posible que no tenga ningún concepto de lo que significa la lógica de múltiples hilos en los juegos. ¿Por qué no simplemente multiprocesar todo, para que el juego pueda aprovechar todos los núcleos que tiene tu PC? Bueno, resulta que no es tan simple. En general, el juego necesita actualizar todas las máquinas, cintas, tuberías, etc., en cada tick. Así es como avanza el tiempo en el juego, permitiéndote jugar en primer lugar. El orden en que esto sucede es importante. Primero, las cintas mueven los artículos en la dirección de la cinta, luego un insertador toma uno objeto y lo coloca en una máquina, luego esa máquina lo usa para fabricar algo.
El problema fundamental que trae el subproceso múltiple es que no puede garantizar el orden en el que suceden las cosas. Cuando realiza múltiples subprocesos en el ejemplo anterior, es posible que la máquina intente crear algo antes de que el insertador inserte el elemento. En ese caso, la máquina no habría podido fabricar porque le faltaba el ingrediente. Si la inserción ocurrió primero, entonces el proceso podría seguir adelante. Este es un problema porque no es determinista. Dependiendo de cómo resulte la lógica enhebrada, la máquina crea un elemento o no, lo que rompe toda la simulación.
Por supuesto, este ejemplo es solo una ilustración del problema. Los problemas reales que surgen son de naturaleza más complicada y técnica. Además, las acciones que utilicé como ejemplos, naturalmente, no suceden todas en un solo tick para una máquina específica; son una analogía para ilustrar el problema en cuestión. No se corresponden necesariamente con la forma en que el juego organiza las cosas.
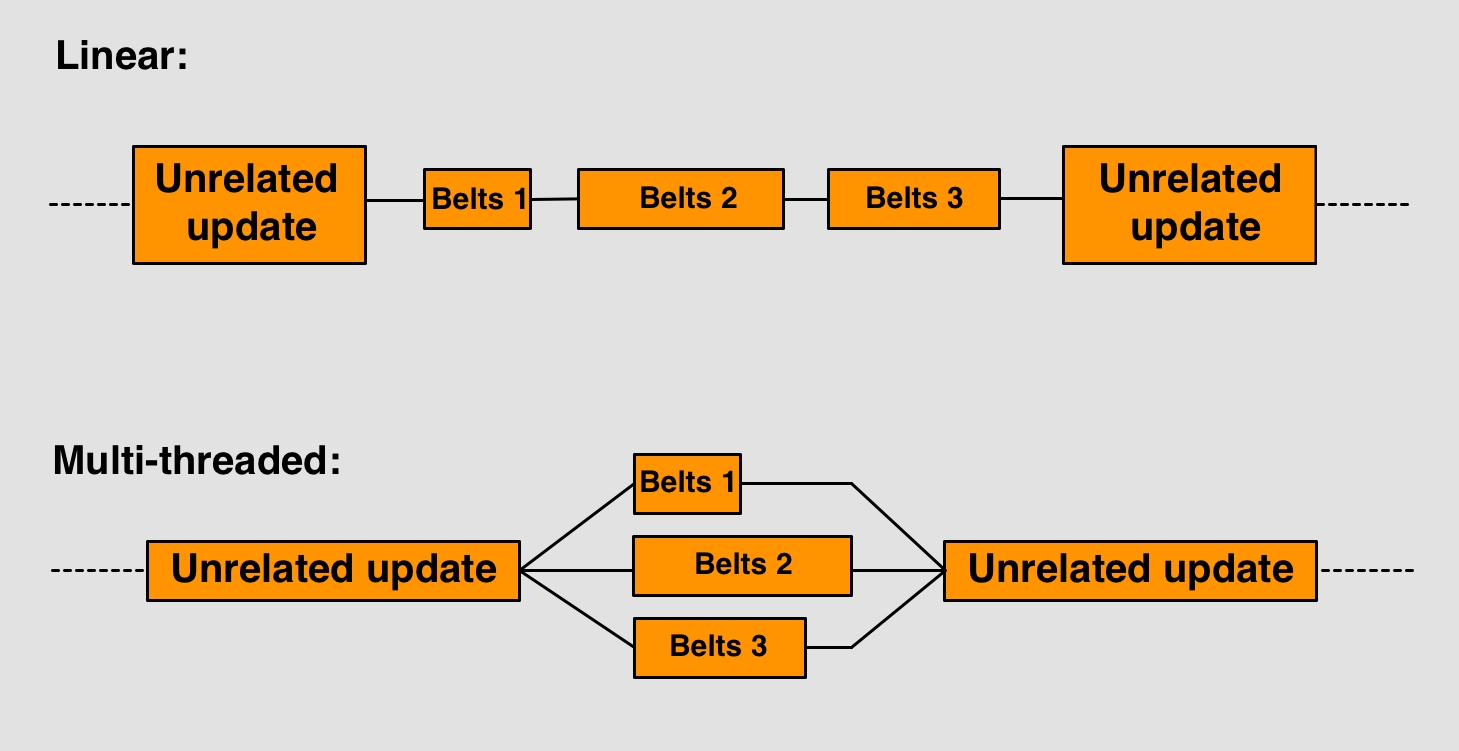
Por lo tanto, en la superficie, parece que no se puede realizar múltiples subprocesos en un juego como Factorio porque rompería la simulación. Todo depende de todo, ¿verdad? Bueno, no del todo. De hecho, siempre habrá partes que deban ejecutarse de una manera estrictamente lineal, pero puede encontrar algunas partes del todo que son realmente independientes entre sí si las observa más de cerca. La lógica del cinturón es una de esas partes.
Cuando lo piensas, cada cinta no está relacionada con todas los demás cintas del mapa. Claro, hay redes gigantes de cintas que están interconectadas, como cuando se ejecuta un bus principal, pero también hay líneas de cintas que no están relacionados con otras en absoluto. De hecho, bastantes ya que los trenes o conjuntos de máquinas tienden a romper las líneas de cintas.

Esto nos permite paralelizar (es decir, multiprocesar) la lógica para actualizar las correas. Ahora, tenemos que tener cuidado; esto no significa que podamos simplemente actualizar las cintas en cualquier momento durante el tick. Todavía es necesario seguir los pasos para mover los artículos, dejar que el insertador los recoja, hacer que la máquina elabore un artículo, en ese orden. Lo que podemos hacer es dividir el movimiento de elementos. Cuando llegamos a ese punto, dividimos la tarea para que cada línea aislada de cintas tenga su propio hilo. Luego, cada hilo mueve los elementos en la línea de cintas que se le ha asignado, por lo que todos se mueven al mismo tiempo, es decir, se procesan en paralelo. Si tenemos cuidado de solo dividir líneas de cintas que no interactúan con otras, podemos actualizarlos de manera segura por su cuenta.
Este enfoque es muy similar a cómo se mejoró la lógica de actualización en los fluidos, como se explica en FFF-271. Esa publicación de blog tiene una visión profunda de cosas como: cómo se cambió el diseño de la memoria para mejorar la eficiencia de la caché, pero ese no es el tema central de este artículo. También hay un hilo de Reddit muy interesante de Varen/Raven hablando sobre la reimplementación de Factorio con multihilo en mente desde el principio. Dale una lectura para ver una conversación técnica extra sobre este tema.
Vamos al meollo: ¿cuál es la diferencia en el mundo real?
Toda esa teoría es interesante y todo eso, pero te estás preguntando cuál es el impacto real en el rendimiento. Bueno, no te preguntes más; ¡Traje gráficos!
Como descargo de responsabilidad, estas mediciones se realizaron en la versión 1.0.0 y 1.1.1 respectivamente. Usé la consola del juego para aumentar la velocidad del juego, lo que me permitió alcanzar UPSs de más de 60. Los números no se midieron con métodos muy rigurosos, lo que significa que tienen un margen de error nada despreciable. Lo que también debe tenerse en cuenta es que el rendimiento de la actualización de las entidades también se incrementó de acuerdo con las notas del parche. Esto también está incluido, aunque no creo que mis medidas sean lo suficientemente precisas como para sacar conclusiones definitivas.
Hice un benchmark de tres bases diferentes con diferentes características, aunque todas usan muchas cintas. Después de todo, no se puede mejorar el rendimiento de lo que no existe. Conozcamos a nuestros concursantes, todos extraídos del increíble sitio web [FactorioBox] (https://factoriobox.1au.us), que tiene una pequeña colección de mapas que son útiles para la evaluación comparativa.
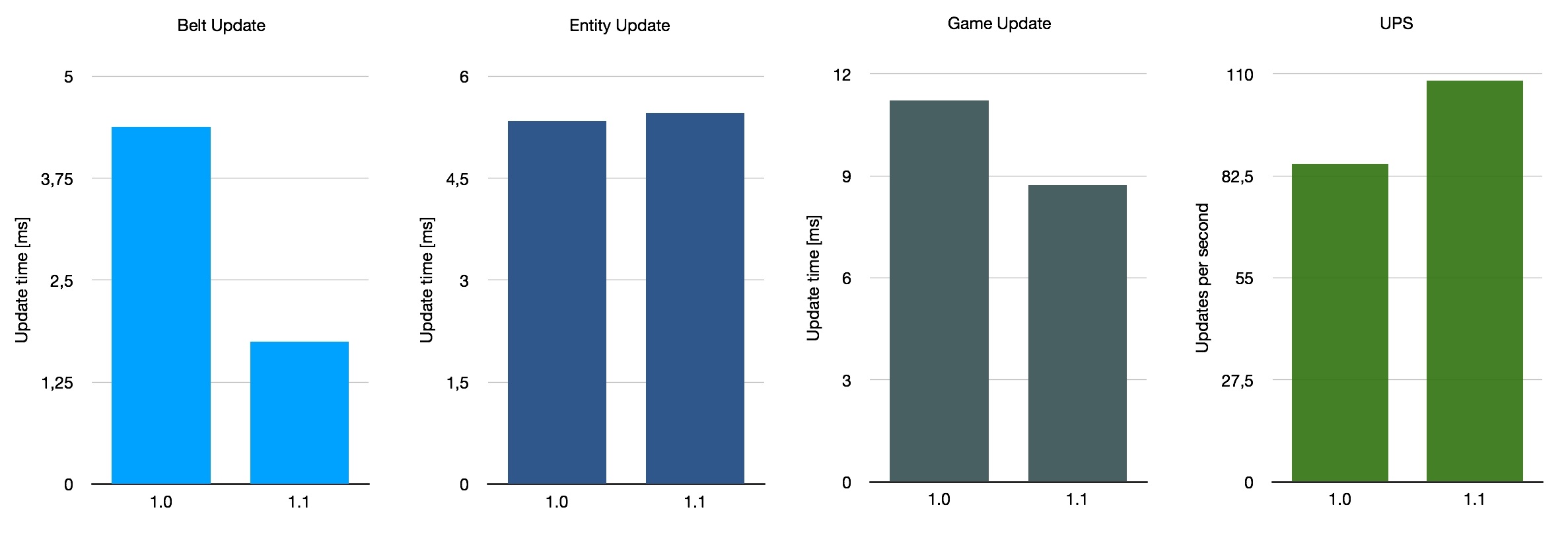
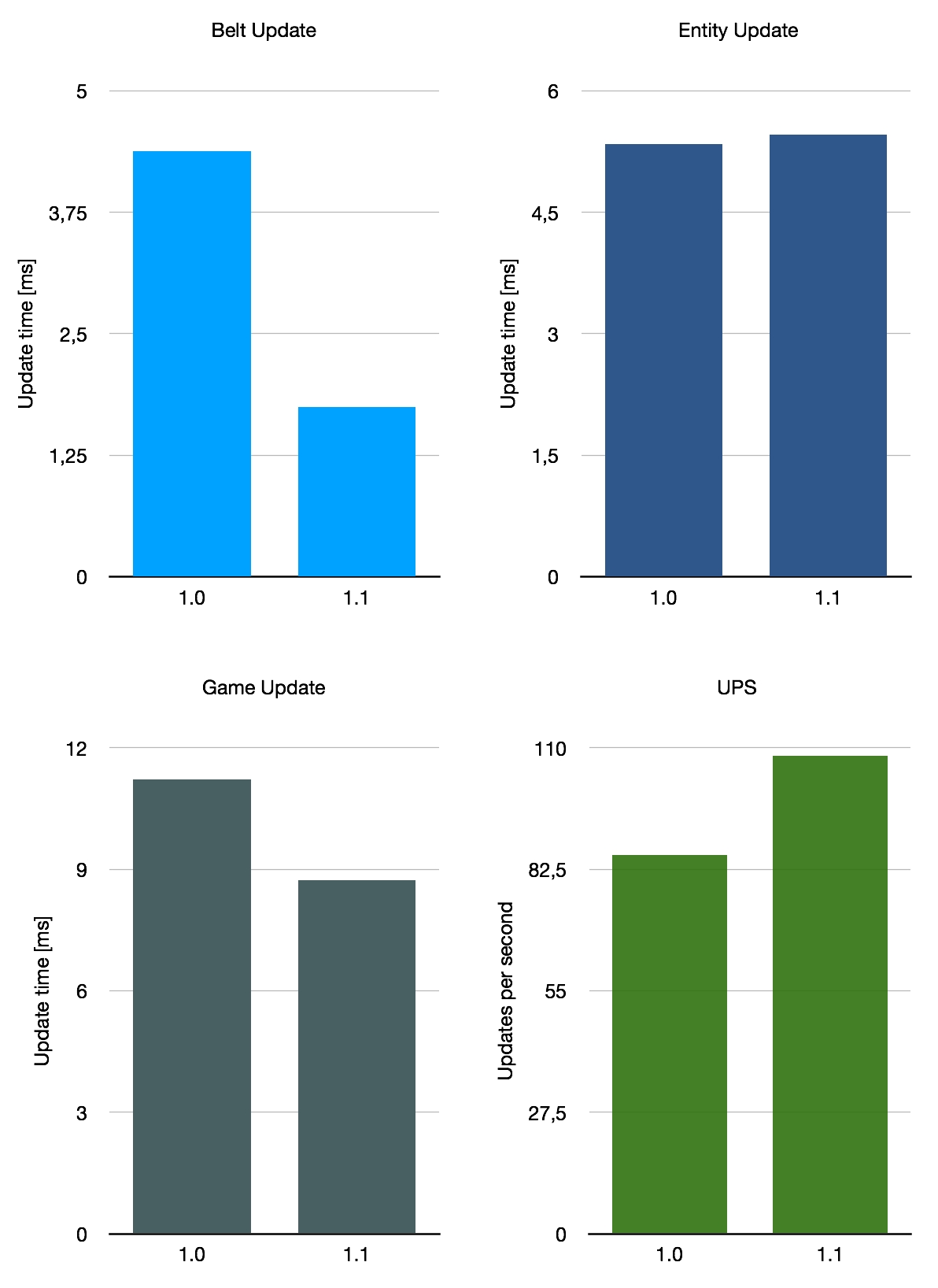
Primero, probé la base de 10k SPM de Stevetrov. Utiliza diseños realmente optimizados para el rendimiento, confiando casi por completo en las cintas. No hay trenes en uso y los bots solo se utilizan en circunstancias muy específicas en las que resultan mejores para el rendimiento que las cintas. Esto lo convierte en un candidato ideal para mostrar el impacto que este cambio puede tener. El efecto no será tan pronunciado en otros casos, ya que los costos de rendimiento se distribuyen más a otras cosas como trenes o bots.
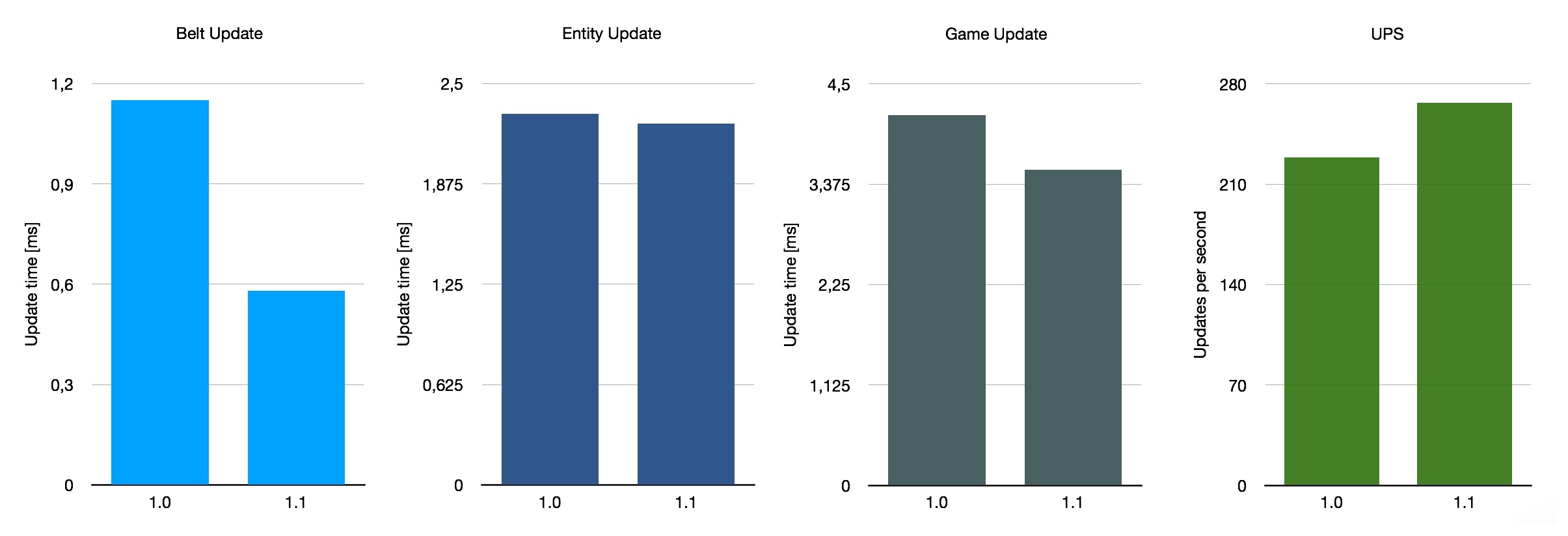
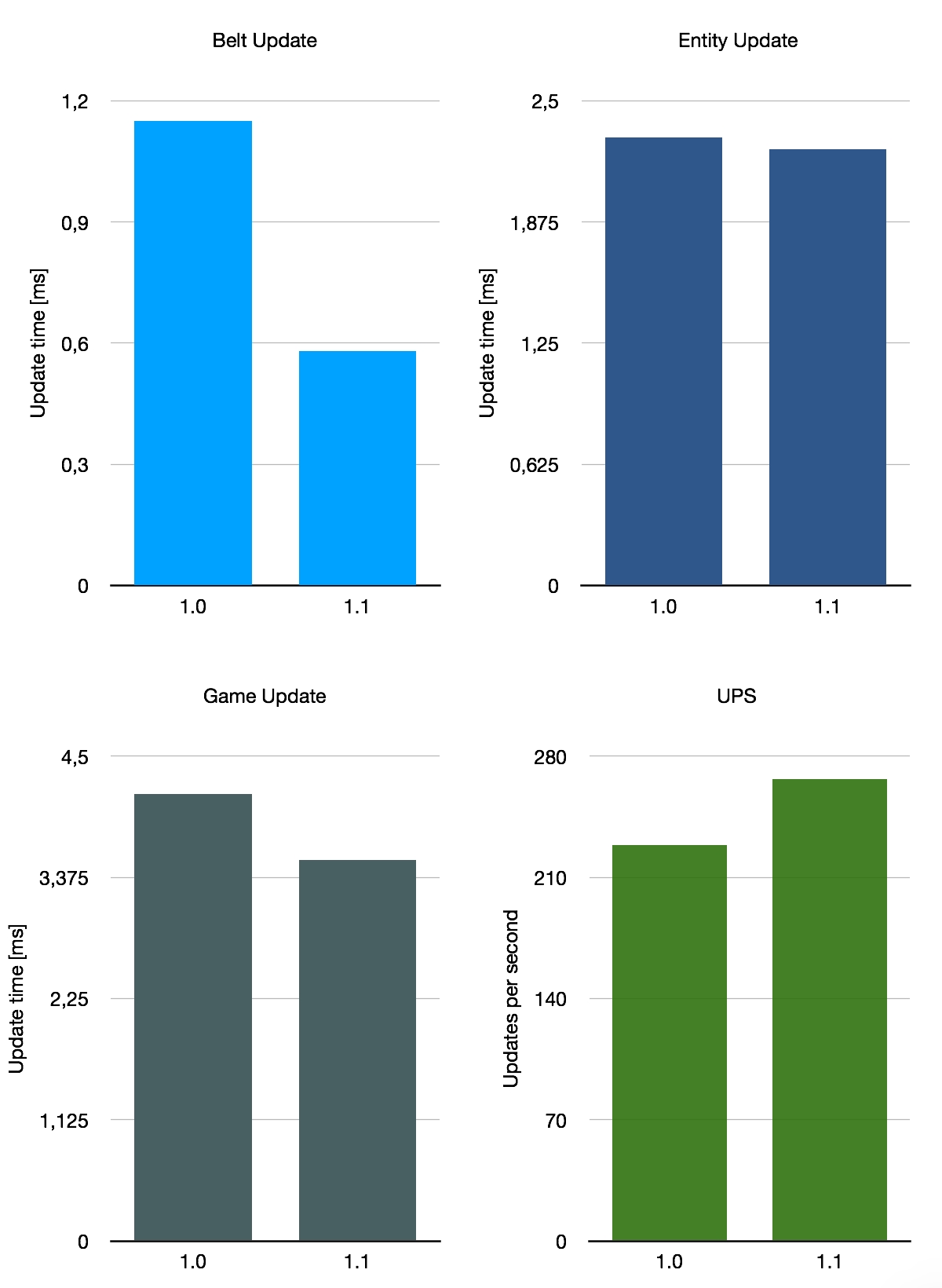
Luego, probé una base cuyo diseño se acerca más a lo que tú o yo podríamos construir. Se llama cam6 en FactorioBox, sin indicación de su origen. Se basa principalmente en cintas, con algunos trenes y bots mezclados. También produce energía mediante reactores nucleares, que tienden a cortar una parte nada despreciable del pastel de rendimiento. Como dije, tiene todo lo que esperaría de un mapa de Factorio común, lo que lo convierte en una buena representación del impacto que puede esperar en su fábrica.
Por último, eché un vistazo a un candidato un tanto inusual: un mapa gigantesco y desordenado titulado Besenovsky Pajzel eque presumiblemente es el nombre de su creador. Se describe como un “mapa enorme (13300x7400 mosaicos) con una producción ineficiente que oscilaba entre 2,4 hasta 4k SPM “. Entonces, este mapa usa una combinación de todas las cosas, con la diferencia más significativa con los dos anteriores siendo el uso extensivo de trenes. Lo que esperamos de esto es que el impacto de las optimizaciones en la 1.1 sea menor ya que lo que se ha mejorado es menos relevante en este mapa.
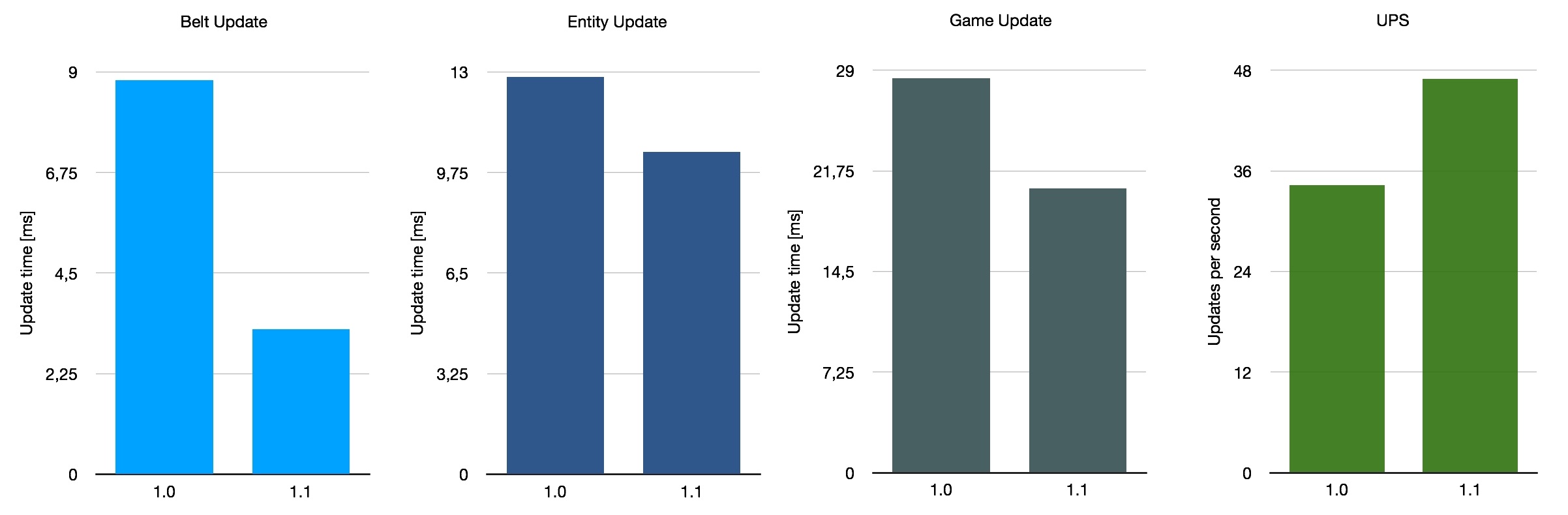
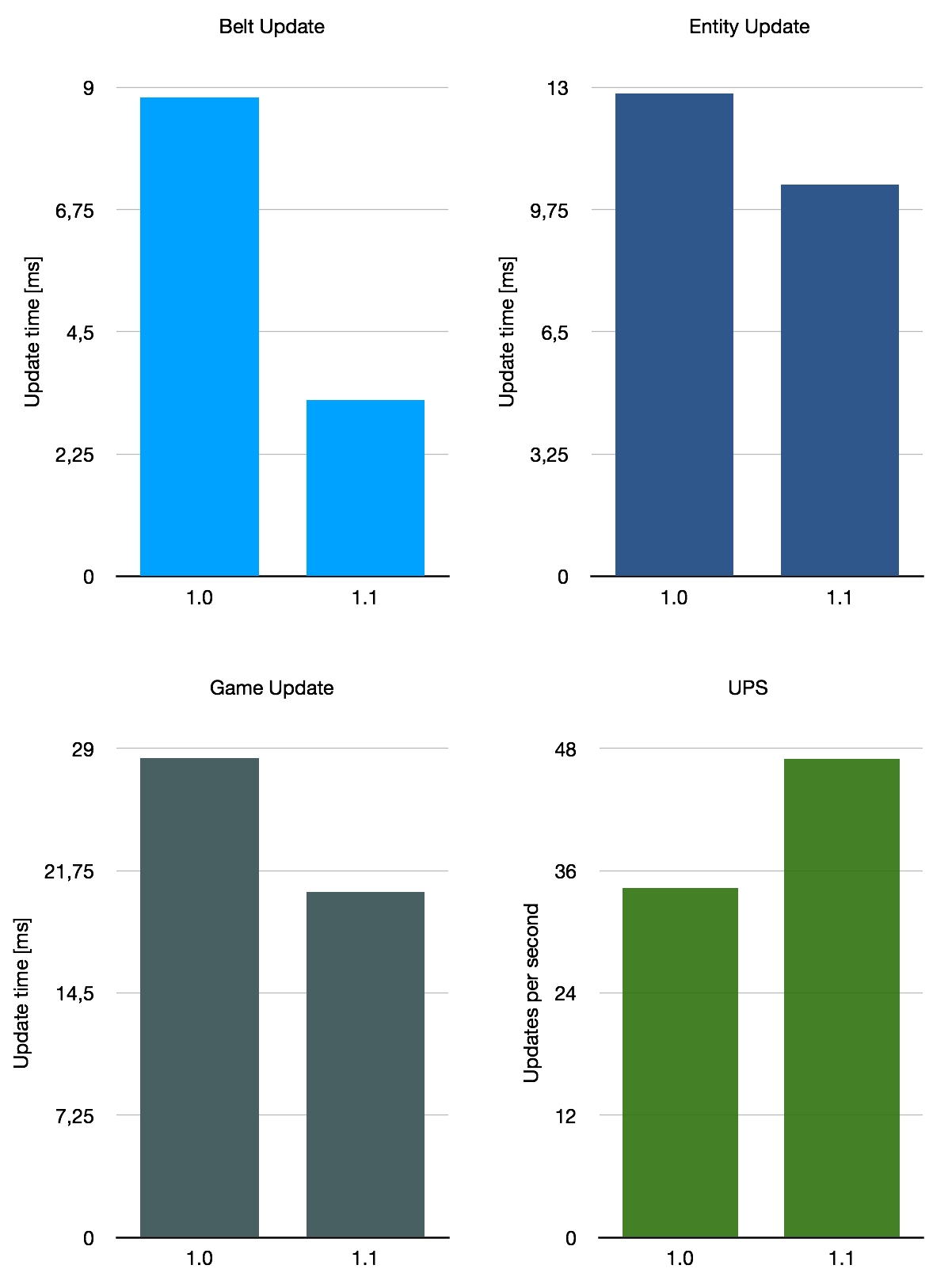
Si promediamos estos tres puntos de referencia muy aproximados, obtenemos una mejora promedio del rendimiento de la cinta del 140%, con UPS subiendo un 26% en promedio. Por supuesto, esto no es representativo del promedio de todos los guardados en uso, ya que solo consideramos estos tres mapas especiales. Con todo, la mejora con 1.1 depende en cierta medida de su diseño base, pero es una buena mejora general.
Después de todo, realmente no importa si una mejora del rendimiento en particular tiene un efecto importante; es la suma de todas las pequeñas mejoras que hacen que el juego se ejecute un orden de magnitud más rápido. Exploramos este efecto hace un par de semanas en en Alt-F4 # 13, y espero que esa base obtenga un repunte adicional en el rendimiento.
Contribuir
Como siempre, buscamos personas que quieran contribuir con Alt-F4, ya sea enviando un artículo o ayudando con la traducción. Si tienes algo interesante en mente que quieres compartir con la comunidad de una manera pulida, este es el lugar para hacerlo. Si no estád muy seguro, con gusto te ayudaremos discutiendo ideas de contenido y preguntas sobre la estructura. Si esto es algo que te gustq, únete a Discord para comenzar.