Alt-F4 n°15 - Exploration de la version 1.1 27-11-2020
traduit par bev

Cette semaine, alors que la version expérimentale 1.1 vient de sortir, nous nous penchons sur deux des éléments qu’elle introduit. Tout d’abord, Conor_ étudie ce que la nouvelle limite d’arrêt de trains lui permet de faire dans son usine utilisant le mod TSM. Ensuite, Therenas explore ce que signifie la mise à jour des convoyeurs en multithread, à la fois en théorie et en pratique. Attention, vous pourriez bien apprendre quelque chose !
Limites d’arrêt de train Conor_
Quand il a été proposé de parler des changements qu’apporte la version 1.1, il fallait évidement que je parle de la nouvelle fonction de limitation de l’arrêt de trains, car j’adore les trains ! Dans ce qui suit, j’examine quel problème cette fonctionnalité résout, et comment je le traitais auparavant.
Une simple erreur d’un Conor_ plus jeune et plus naïf
Il y a quelque temps, je construisais l’une de mes premières grandes bases pour essayer de vaincre le mod SpaceX en multipliant par 5 les coûts des recherches (parce que Pourquoi pas ?) lorsque j’ai remarqué des problèmes dans mon réseau de trains spaghetti™. En raison de l’ignorance de ma jeunesse, j’avais décidé que les arrêts pour un matériau donné devaient avoir le même nom, en déployant un grand nombre de trains pour circuler entre ces arrêts afin de s’assurer qu’ils soient tous utilisés. Ce n’était pas une bonne idée. Ce système simple à mettre en œuvre a entraîné des douleurs et des souffrances, comme je n’en avais plus connues depuis mes tentatives de comprendre le traitement du pétrole. Cela avait bien fonctionné pour moi sur de petites bases avec seulement quelques arrêts répartis sur une courte distance, mais à grande échelle, les trains n’allaient tout simplement pas vers les avant-postes plus éloignés. Certains arrêts étaient bloqués et provoquaient des embouteillages, tandis que d’autres étaient déserts. J’ai décidé qu’il devait y avoir une meilleure solution, et comme le bon ingénieur que je suis, j’ai travaillé dur pour rechercher et développer une meilleure solution au problème demandé à Reddit.
Quelqu’un connaît-il un mode de transport qui répartit équitablement les trains entre les arrêts de même nom, quelle que soit la différence de distance. Par exemple, tous les arrêts de déchargement du fer sont appelés de la même façon, mais un nombre égal de trains se rendent à chacun des différents arrêts.
Does anyone knows of a mod that will equally distribute trains between stops of the same name, irrelevant of the distance difference. E.g. All iron unload stops called one thing but an equal number of trains go to each of the different stops.
— Conor_ (Août 2019)
Quel beau rêve de puissance j’ai eu là. Au lieu de ce que je demandais, on m’a dirigé à juste titre vers TSM et LTN, puis on m’a dit de poursuivre ma route. Mais avec la version 1.1, les développeurs ont crié depuis les hauteurs, “Nous avons une nouvelle fonctionnalité pour le train !” OK développeurs, je vous écoute…
Que sont les limites d’arrêt de train ?
La limite d’arrêt de trains, telle que décrite dans le FFF-361, vous permet de régler le nombre de trains à un arrêt donné. Les détails techniques de ce système sont beaucoup plus détaillés dans le FFF (qui vaut certainement la peine d’être lu), mais en résumé, un train ne devrait se rendre à un arrêt que s’il y a de la place pour le recevoir, ce qui est exactement ce que voulait le jeune Conor_. Mais est-ce que cela tient la route par rapport à mon nouvel amour, TSM ?
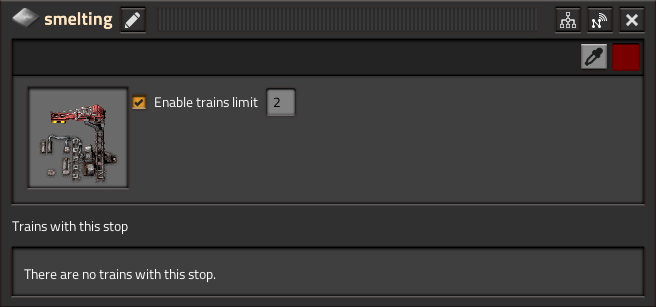
Qu’est-ce que TSM et pourquoi devrais-je m’en inquiéter ?
Train Supply Manager (TSM) est un mod qui permet aux arrêts de trains de demander un train lorsque certaines conditions logiques sont remplies. Un exemple pertinent pour une telle condition serait de demander un train lorsque moins d’un certain nombre de trains sont en route vers l’arrêt. Il vous permet également de faire de la magie logique plus complexe, par exemple en ne demandant un train que lorsqu’il y a assez de matériau pour le remplir réellement, bien que je n’aie jamais utilisé cette fonctionnalité.
Le rêve de TSM est de mettre pleinement en œuvre un système logistique basé sur la demande plutôt que sur l’offre, comme c’est le cas pour des configurations plus élémentaires. La stratégie habituelle de l’offre est celle que l’on retrouve dans de nombreuses petites usines où les trains sont remplis à l’avant-poste, puis évacués, pour patienter à la destination. Avec un système de demande, les trains sont toujours prêts à livrer ou à être chargés, et ne sont appelés que lorsque des ressources sont nécessaires.
La différence réside dans le choix du moment où les trains sont mis en marche ; dans le cas d’un système basé sur l’offre, le moment est fixé par la vitesse à laquelle les arrêts peuvent remplir les trains et les mettre en route, indépendamment du nombre de ressources dont l’usine a besoin. En passant à un système basé sur la demande, le moment est déterminé par les arrêts de destination, ce qui leur permet de ne demander des trains que lorsqu’ils sont réellement nécessaires. Cela vous permet de réduire massivement le nombre de trains en mouvement sur un réseau donné et de contrôler où les trains attendent pour s’assurer qu’ils ne provoquent pas de congestion. Bien que cela soit également possible avec le jeu de base en utilisant de grandes zones d’attente pour les trains, en planifiant soigneusement où les trains en attente doivent s’arrêter, ce n’est pas très idéal ni pratique. Dans ce système, les trains sont attendus à la fois aux arrêts de récupération et de livraison, ce qui est particulièrement important pour les grandes bases et c’est la raison pour laquelle j’aime tant TSM.
Les limites d’arrêt de trains peuvent-elles remplacer TSM ?
Pour comprendre quand il faudra utiliser TSM plutôt que la nouvelle fonction de limitation des arrêts de train, j’ai recréé la fonctionnalité de TSM dans le jeu normal en 1.1, sans TSM, avec beaucoup de succès !
La raison pour laquelle ce système fonctionne à merveille et remplace si bien TSM, c’est que les trains attendent à l’arrêt du dépôt jusqu’à ce qu’il y ait de la place dans la gare de chargement ou de déchargement. Si les trains devaient attendre au point de chargement, cela provoquerait des encombrements et limiterait le débit du producteur. L’utilisation des arrêts de dépôt permet aux trains de disposer d’une sorte de “zone d’attente” à l’écart du reste du réseau ferroviaire, le temps qu’ils deviennent à nouveau nécessaires.
Comme nous pouvons le voir, l’ensemble de ce système peut être recréé avec la nouvelle fonction du jeu, probablement avec de meilleures performances en raison de son intégration directe au jeu. Cela ne tient même pas compte de la plus grande simplicité de la limite d’arrêt de trains par rapport à la compréhension de TSM, qui a une courbe d’apprentissage assez raide et une documentation qui est loin d’être parfaite. TSM peut encore être utile dans certains cas, par exemple lorsque le joueur souhaite obtenir des informations sur les demandes actuellement non satisfaites que TSM fournit via son interface, bien que personnellement je n’utilise que rarement ces fonctionnalités.
Conclusion
Il arrive souvent que les développeurs de jeux avec possibilité de mods remarquent une fonctionnalité intéressante et l’implémentent dans le jeu de base. Cela peut être un peu douloureux pour les créateurs de mods car cela rend leur mod pour la plupart obsolète, mais au final, ils ont réussi à améliorer le jeu. Leur mod est maintenant indirectement intégré dans le jeu qu’ils aiment, ce qui signifie que plus de gens peuvent l’utiliser, ce qui est formidable.
Je remercie tout particulièrement sorahn du serveur Discord de Factorio d’avoir repéré mes questions et d’avoir fait tout son possible pour m’aider, en réalisant la carte que j’ai modifiée ci-dessus pour illustrer comment TSM peut fonctionner dans la configuration “double requête”, ainsi que pour avoir vérifié l’équilibre mental de mes idées avant que je ne les construise.
Cette fonction sera étonnante pour les nouveaux joueurs (comme le Conor_ jeune et naïf) qui pourront ainsi construire plus facilement des réseaux de trains plus vastes et plus élaborés. Elle offre une autre fonction facile à apprendre et difficile à maîtriser, que les joueurs expérimentés pourront utiliser et explorer, tout en aidant les débutants à s’amuser.
Améliorations des performances avec la version 1.1 Therenas
La dernière version expérimentale de Factorio a apporté de nombreux changements, dont un que je souhaite examiner de plus près aujourd’hui. Il se cache discrètement dans le journal des modifications de la version 1.1.0 et n’a été mentionné dans aucune des éditions des FFF précédant la sortie. Ce n’est que quelques mots : Mise à jour de la logique des convoyeurs en multithread. Je suis ici pour découvrir ce que cela signifie et quel est son impact réel.
Comment cette optimisation fonctionne-t-elle sur le plan technique ?
Maintenant, vous n’avez peut-être pas la moindre idée de ce que signifie la logique des jeux en multithread. Pourquoi ne pas simplement tout mettre en œuvre en multithread, afin que le jeu puisse tirer parti de tous les processeurs de votre PC ? Eh bien, il s’avère que ce n’est pas si simple. En général, le jeu doit mettre à jour toutes les machines, convoyeurs, tuyaux, etc. à chaque tick. C’est ainsi que le temps progresse réellement dans le jeu, ce qui vous permet de jouer, en premier lieu. L’ordre dans lequel cela se produit est important. D’abord, les convoyeurs déplacent les objets dans la direction du convoyeur, puis un bras en prend un et le met dans une machine, puis cette machine l’utilise pour fabriquer quelque chose.
Le problème fondamental que pose le multithread est qu’il ne permet pas de garantir l’ordre dans lequel les choses se déroulent. Dans l’exemple précédent, il se peut que la machine essaie de fabriquer quelque chose avant que le bras n’insère l’objet. Dans ce cas, la machine n’aurait pas pu fonctionner car il lui manquait l’ingrédient. Si l’insertion se faisait en premier, la machine pourrait alors travailler. C’est un problème parce que ce n’est pas déterministe. En fonction de la logique du traitement informatique, la machine peut fabriquer un objet ou non, ce qui brise la simulation.
Cet exemple n’est bien sûr qu’une illustration du problème. Les problèmes réels qui apparaissent sont plus compliqués et de nature technique. De plus, les actions que j’ai utilisées comme exemples ne se produisent naturellement pas toutes en un tick pour une machine spécifique ; elles sont une analogie pour illustrer le problème en question. Elles ne correspondent pas nécessairement à la façon dont le jeu organise réellement les choses.
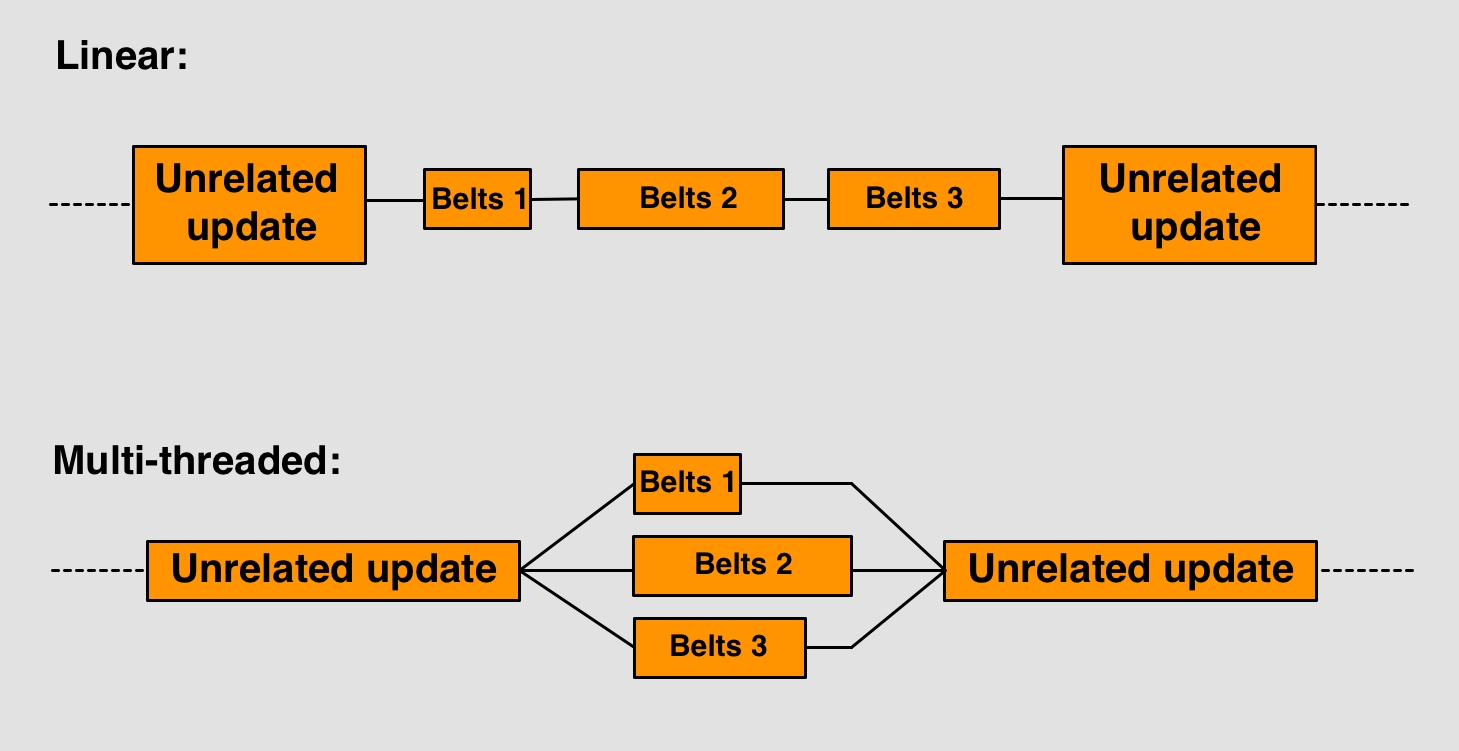
Donc, à première vue, il semble qu’on ne puisse pas faire du multithread dans un jeu comme Factorio parce que cela briserait la simulation. Tout dépend de tout, n’est-ce pas ? Eh bien, pas tout à fait. En effet, il y aura toujours des étapes qui devront être exécutées de manière strictement linéaire, mais vous pouvez trouver des parties de l’ensemble qui sont vraiment indépendantes les unes des autres si vous y regardez de plus près. La logique du convoyeur en est une.
Quand on y pense, chaque convoyeur n’est pas lié à tous les autres sur la carte. Bien sûr, il y a des réseaux de convoyeurs géants qui sont interconnectés, comme dans un bus principal, mais il y a aussi des lignes de convoyeurs qui ne sont pas du tout reliées entre elles. En fait, il y en a beaucoup, car les trains ou les réseaux de machines ont tendance à briser les lignes de convoyeurs.

Cela nous permet de paralléliser (c’est-à-dire travailler en multithread) la logique de mise à jour des convoyeurs. Nous devons maintenant être prudents ; cela ne signifie pas que nous pouvons simplement mettre à jour les convoyeurs à n’importe quel moment pendant le tick. Il faut encore passer par les étapes consistant à déplacer les objets, à laisser le bras les ramasser, à faire fabriquer un objet par la machine, et ce dans cet ordre. La chose que nous pouvons faire est de séparer le déplacement des objets. Lorsque nous arrivons à ce point, nous répartissons la tâche de manière à ce que chaque ligne de convoyeurs isolée ait son propre processus. Chaque processus déplace ensuite les objets sur la ligne de convoyeurs qui lui a été attribuée, de sorte qu’ils se déplacent tous en même temps, c’est-à-dire qu’ils sont traités en parallèle. Si nous prenons soin de ne séparer que les lignes de convoyeurs qui n’interagissent pas avec d’autres, nous pouvons les mettre à jour en toute sécurité de manière autonome.
Cette approche est très similaire à la façon dont la logique de mise à jour des fluides a été améliorée, comme indiqué dans le FFF n°271. Cet article du blog donne un aperçu de la manière dont la disposition de la mémoire a été modifiée pour améliorer l’efficacité de la cache, mais ce n’est pas le sujet de cet article. Il y a aussi un fil de discussion Reddit très intéressant de Varen/Raven qui parle de la refonte de Factorio en ayant la logique en multithread à l’esprit dès le départ. Lisez-le pour obtenir des informations techniques supplémentaires sur ce sujet.
Au travail maintenant : quelle est la différence en pratique ?
Toute cette théorie est bien belle, mais vous vous demandez quel est l’impact réel sur les performances. Eh bien inutile de vous poser ces questions, j’ai apporté des graphiques !
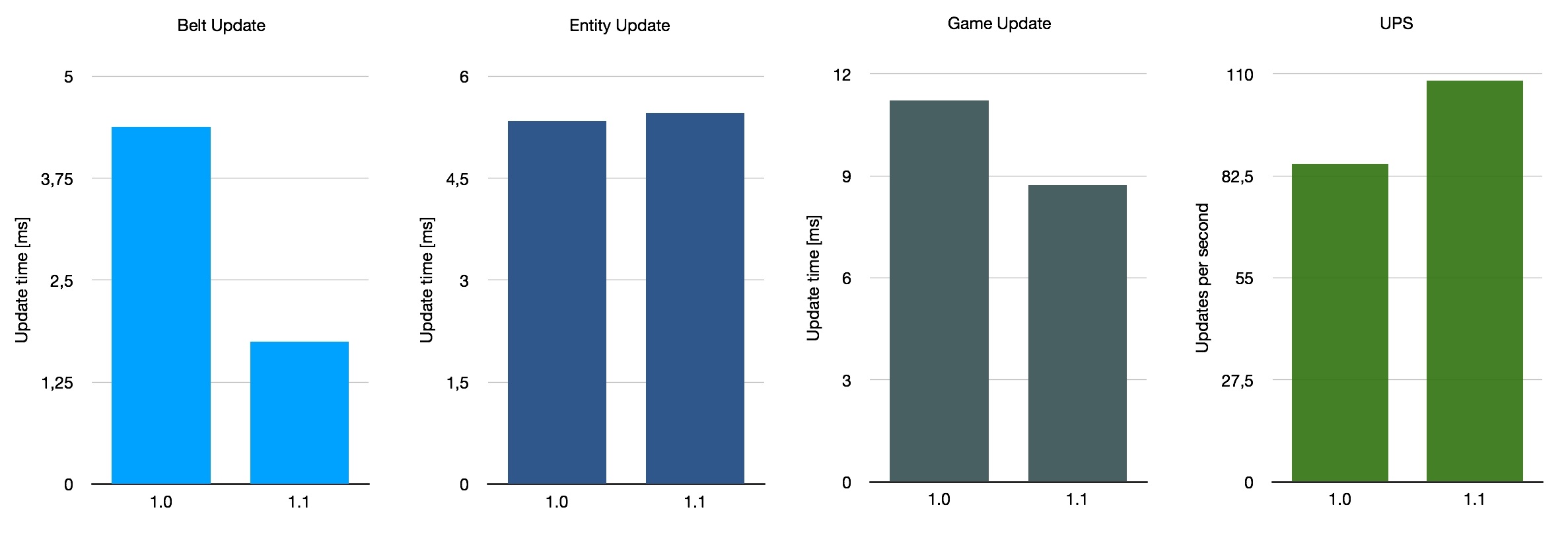
À titre d’avertissement, ces mesures ont été effectuées sur les versions 1.0.0 et 1.1.1 respectivement. J’ai utilisé la console de jeu pour augmenter la vitesse du jeu, ce qui m’a permis d’obtenir un UPS de plus de 60. Les chiffres n’ont pas été mesurés avec des méthodes très rigoureuses, ce qui signifie qu’ils ont une marge d’erreur non négligeable. Il faut également tenir compte du fait que les performances de mise à jour de l’entité ont également été augmentées selon les notes de correctifs. Ceci est également inclus, bien que je ne pense pas que mes mesures soient suffisamment précises pour tirer des conclusions définitives.
J’ai comparé trois sauvegardes différentes avec des caractéristiques différentes, bien qu’elles utilisent toutes beaucoup de convoyeurs. On ne peut pas améliorer les performances de celles qui n’existent pas, après tout. Rencontrons nos concurrents, qui sont tous issus de l’étonnant site web FactorioBox qui propose une petite collection de cartes utiles pour la comparaison des performances.
Tout d’abord, j’ai testé la base à 10 000 SPM de Stevetrov. Elle utilise des configurations vraiment optimisées en termes de performances, reposant presque entièrement sur des convoyeurs. Aucun train n’est en service, les robots n’étant utilisés que dans des circonstances très spécifiques où ils s’avèrent plus performants que les convoyeurs. Cela en fait un candidat idéal pour montrer l’impact que ce changement peut avoir. L’effet ne sera pas aussi prononcé dans d’autres cas, car les coûts de performance sont davantage répartis sur d’autres éléments comme les trains ou les robots.
Ensuite, j’ai testé une base dont la disposition est plus proche de ce que vous ou moi pourrions construire. Elle s’appelle simplement cam6 sans aucune indication quant à son origine. Elle repose principalement sur des convoyeurs, avec quelques trains et robots en plus. Elle produit également de l’électricité à l’aide de réacteurs nucléaires, qui ont tendance à couper une part non négligeable du gâteau des performances. Comme je l’ai dit, elle a tout ce que l’on peut attendre d’une carte habituelle de Factorio, ce qui en fait une bonne représentation de l’impact que vous pouvez attendre sur votre usine.
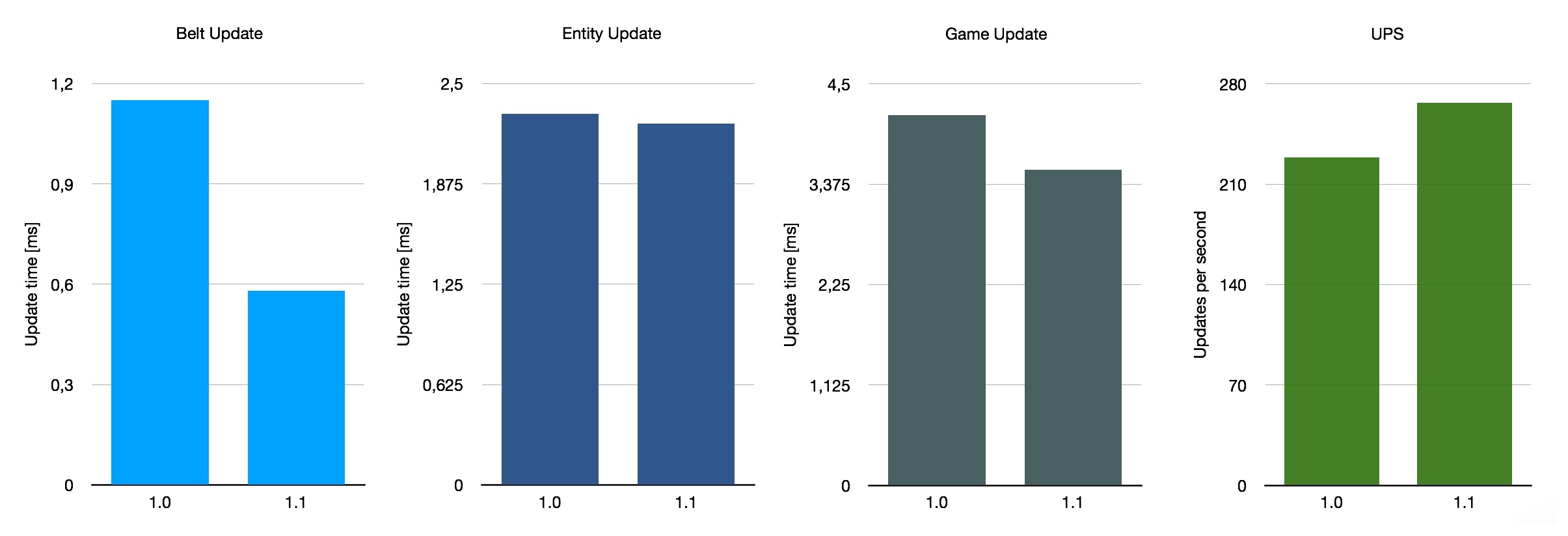
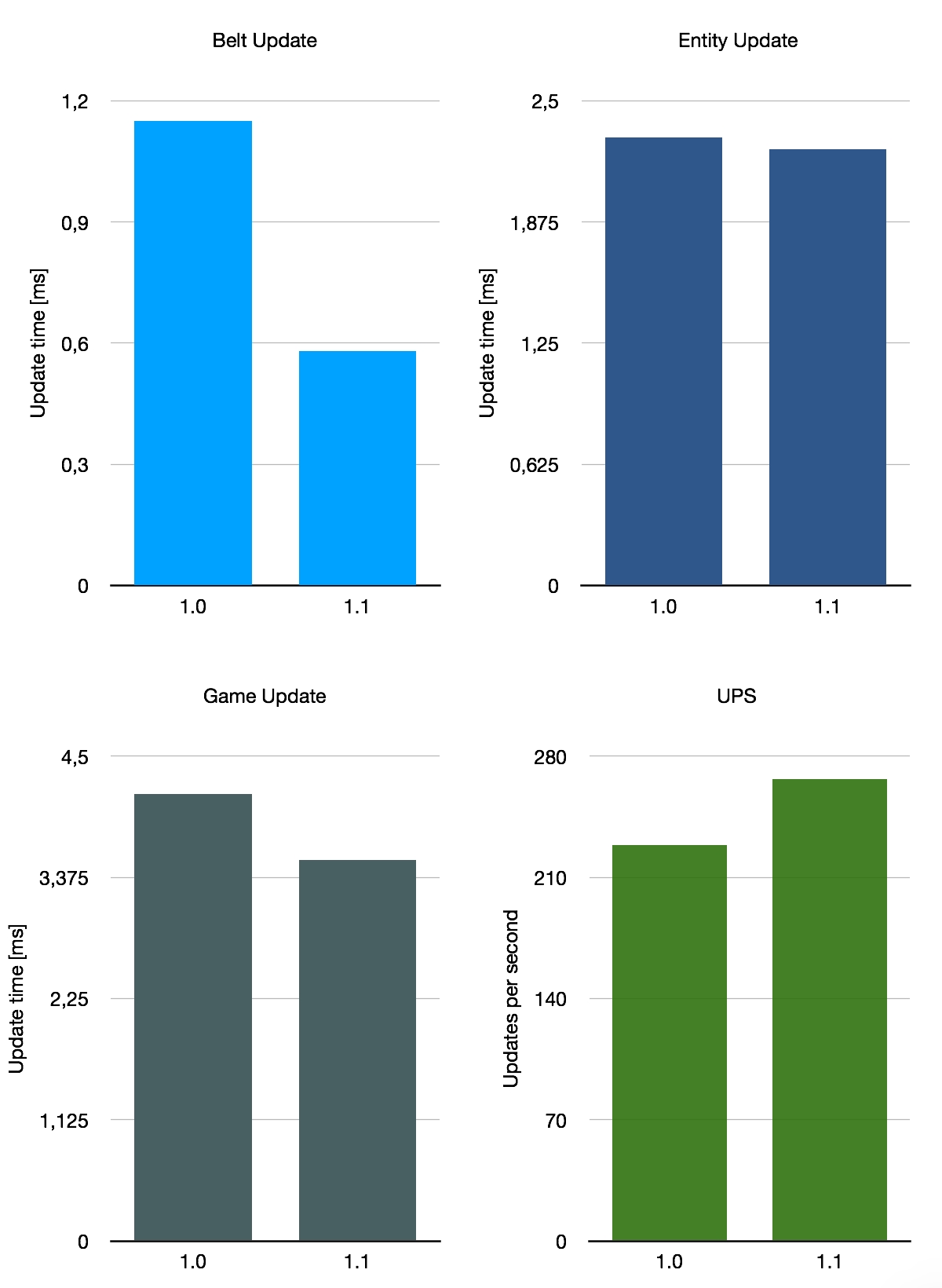
Enfin, j’ai jeté un coup d’œil sur un candidat quelque peu inhabituel : une gigantesque carte désordonnée intitulée Besenovsky Pajzel, qui est probablement le nom de son créateur. Elle est décrite comme une “énorme carte (13300x7400 tuiles) avec une production inefficace allant de 2400 à 4000 SPM”. Cette carte utilise donc un mélange de tous ces éléments, la différence la plus significative avec les deux précédentes étant l’utilisation intensive des trains. Ce que nous en attendons, c’est que l’impact des optimisations de la version 1.1 soit moins important, car ce qui a été amélioré est moins pertinent sur cette carte.
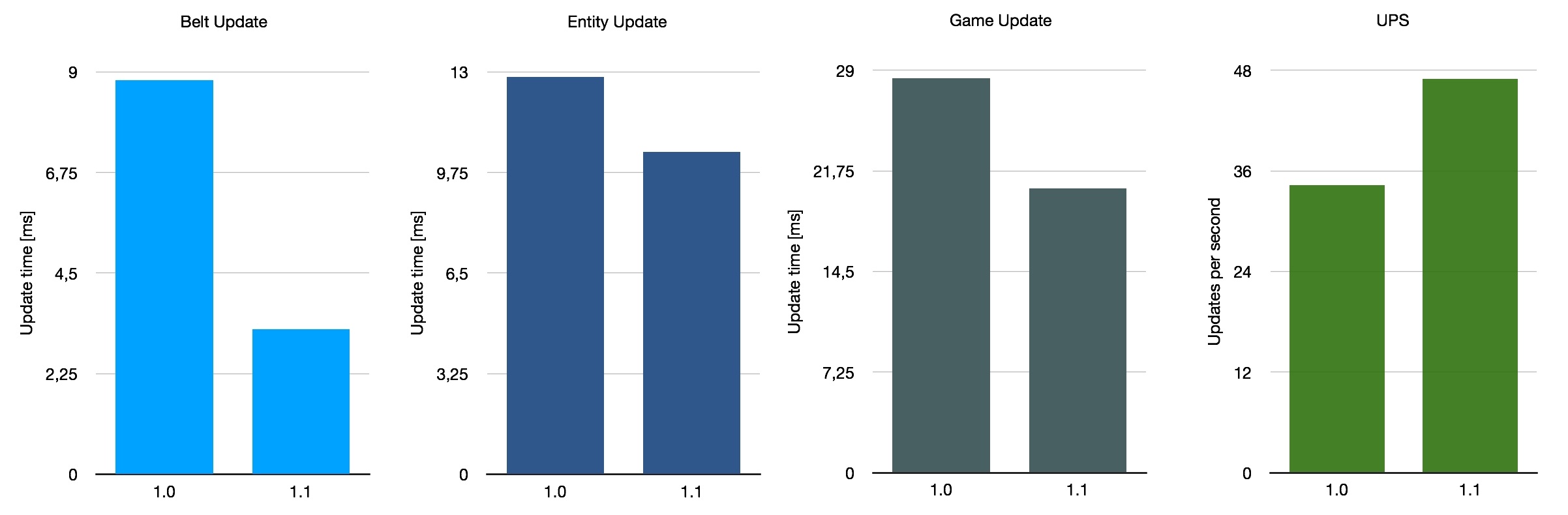
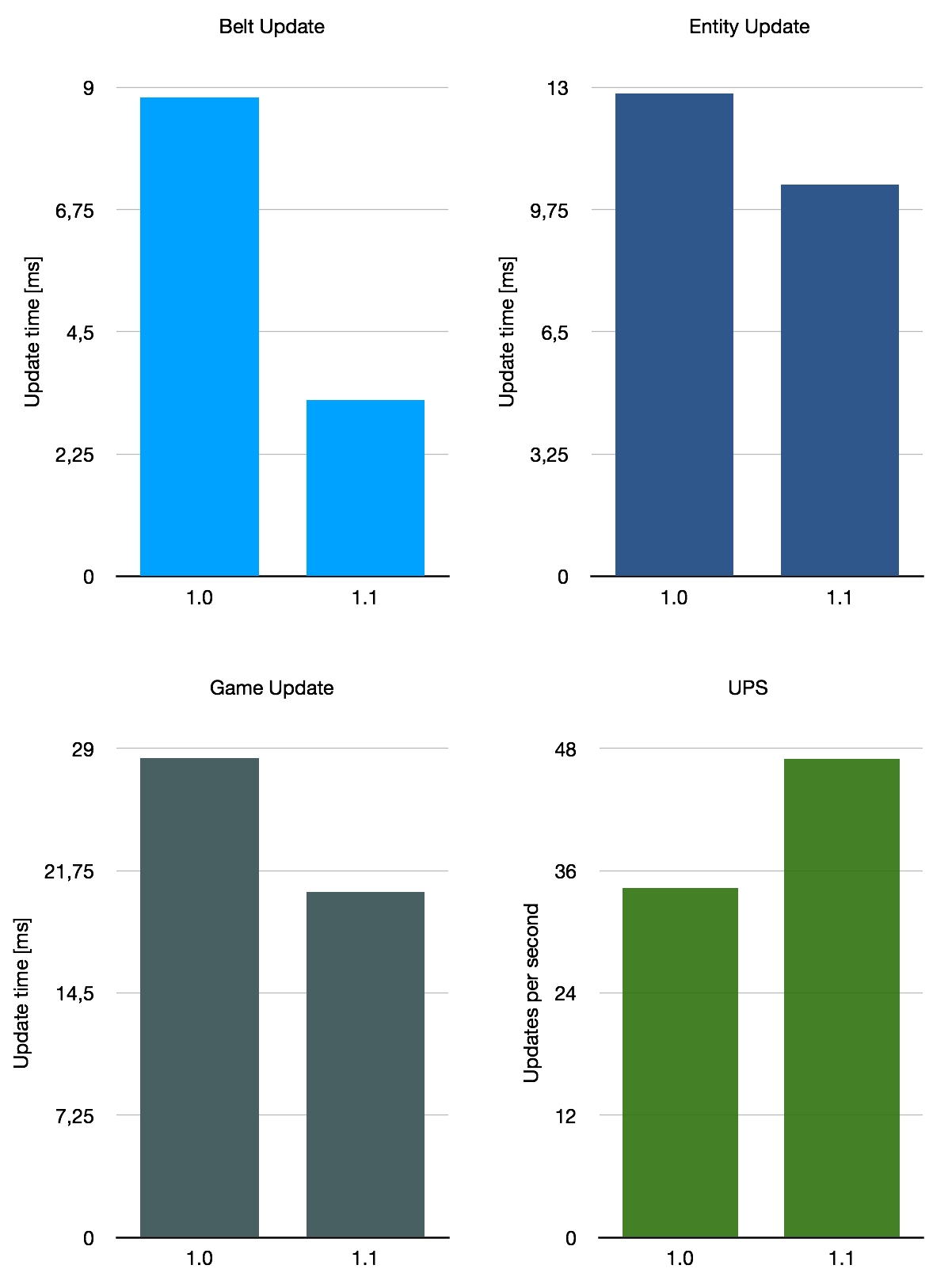
Si nous faisons la moyenne de ces trois critères très approximatifs, nous obtenons une amélioration moyenne de 140 % des performances des convoyeurs, avec une augmentation moyenne de 26 % pour les UPS. Cela n’est pas représentatif de la moyenne de toutes les sauvegardes possibles en utilisation, bien sûr, car nous n’avons pris en compte que ces trois cartes spéciales. Dans l’ensemble, l’amélioration avec la version 1.1 dépend quelque peu de la configuration de votre base, mais c’est une belle amélioration générale.
Après tout, peu importe qu’une amélioration particulière des performances ait un effet important ; c’est la somme de toutes les petites améliorations qui font que le jeu tourne plus vite d’un ordre de grandeur. Nous avons étudié cet effet il y a quelques semaines dans le Alt-F4 n°13, et je m’attends à ce que cette base obtienne une amélioration supplémentaire des performances.
Contribuer
Comme toujours, nous attendons vos contributions pour les Alt-F4, que cela soit par la soumission d’un article ou en aidant pour les traductions. Si vous avez quelque chose d’intéressant en tête que vous souhaitez partager avec la communauté, vous êtes au bon endroit. Si vous n’êtes pas sûr, nous serons heureux de vous aider en discutant structure, contenu et idées. Donc si vous voulez vous impliquer dans les Alt-F4, rejoignez-le Discord pour ne rien rater !